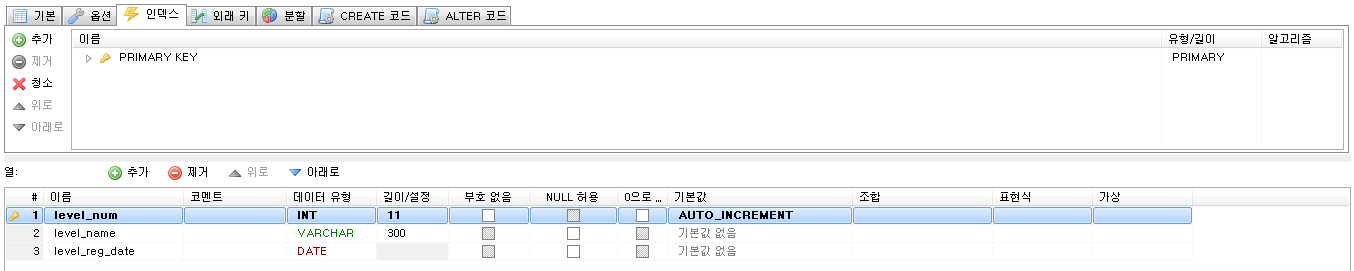
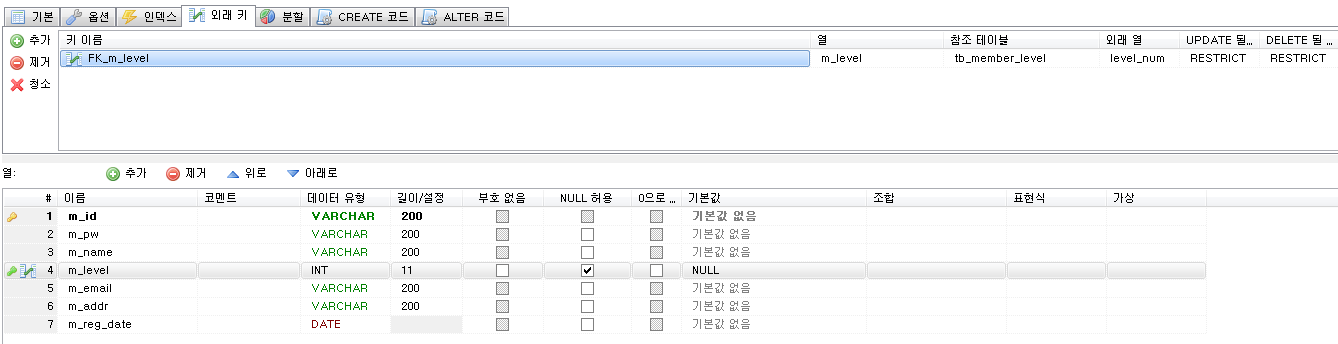
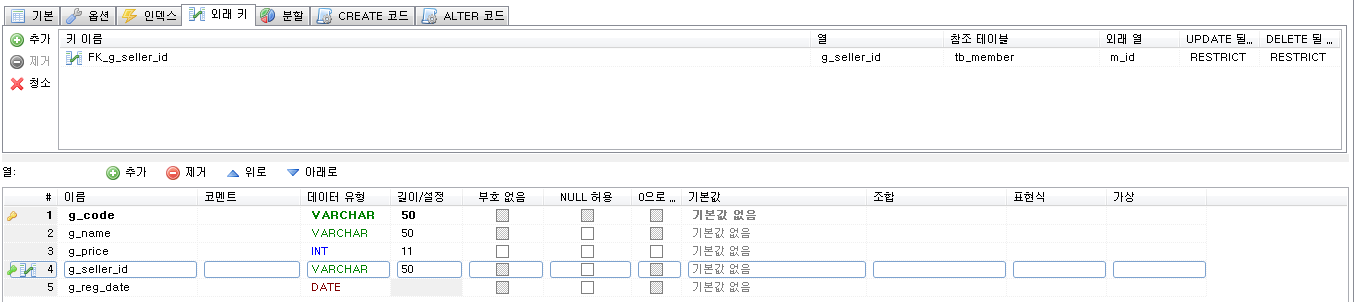
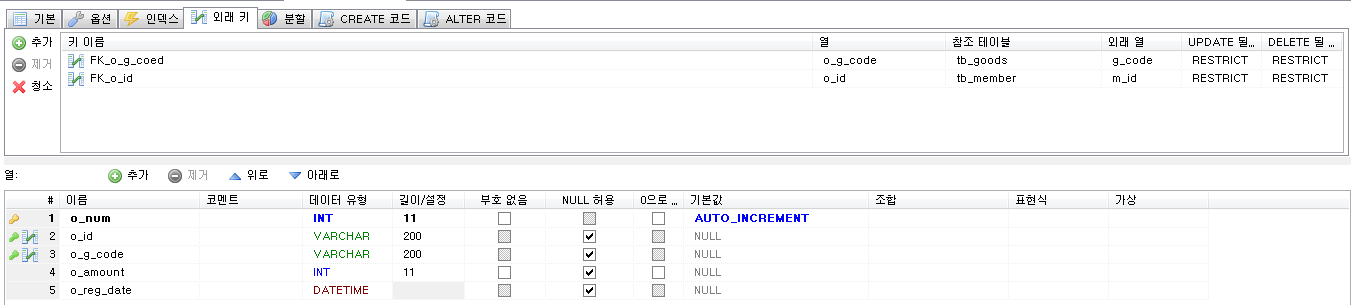
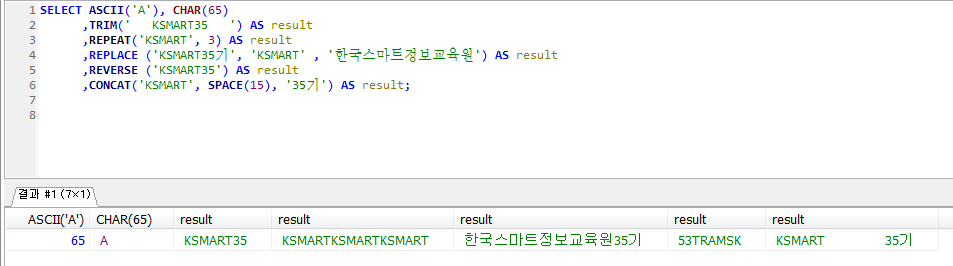
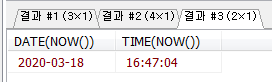
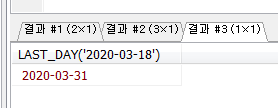
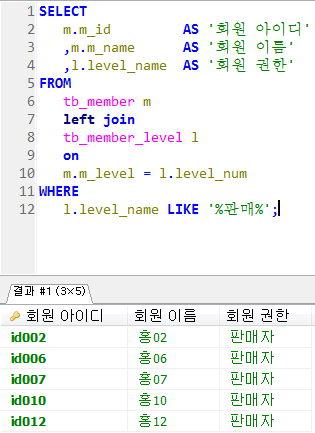
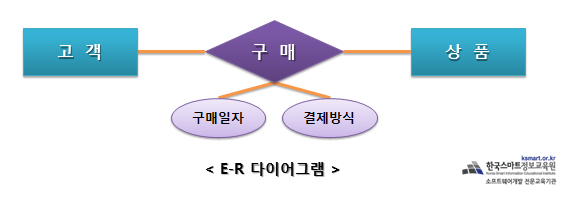
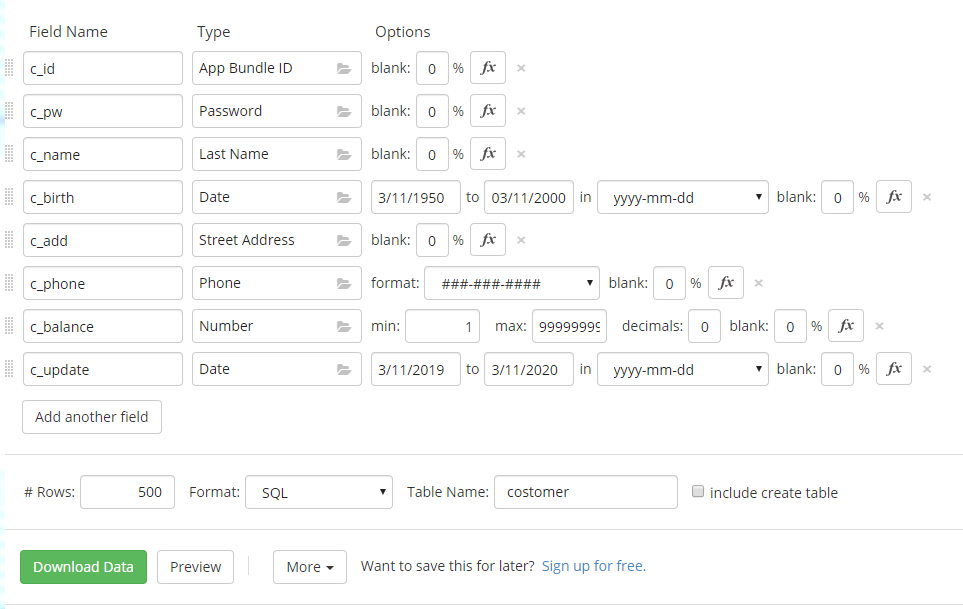
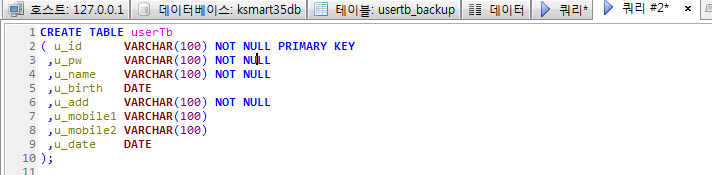
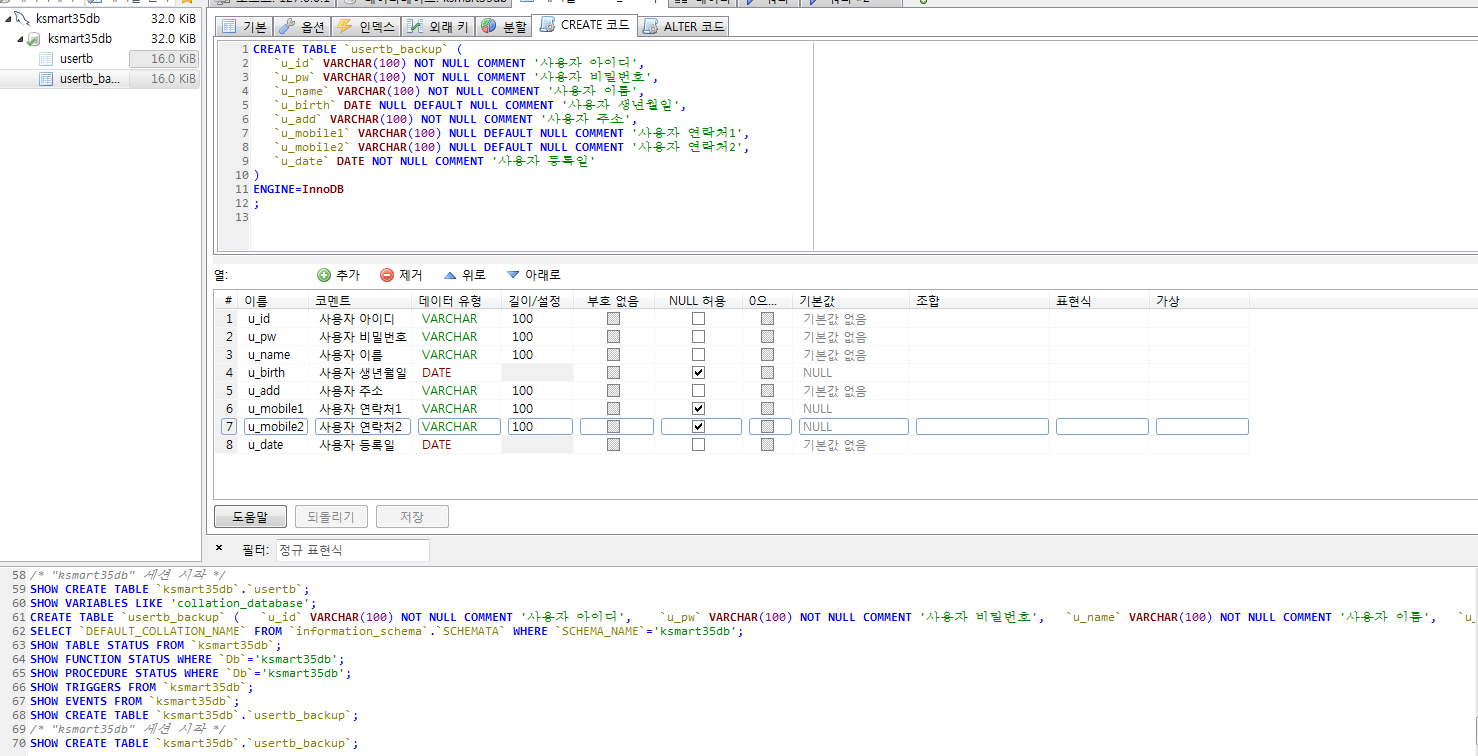
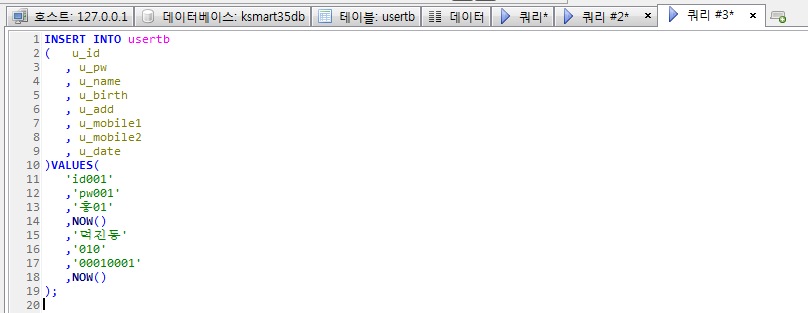
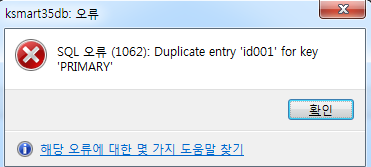
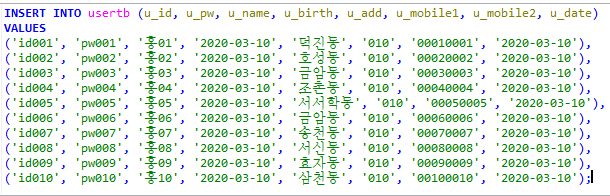
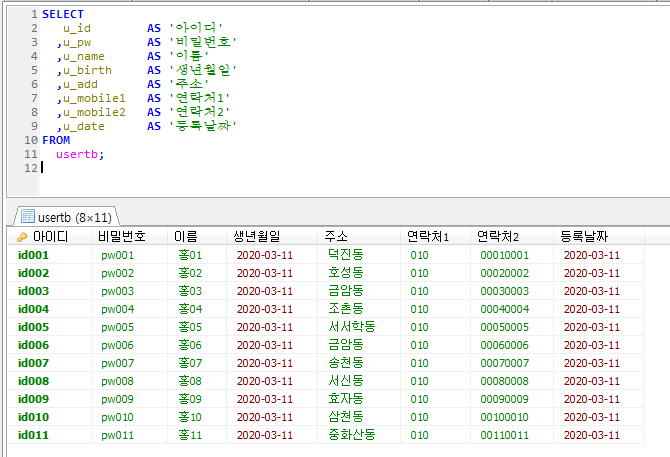
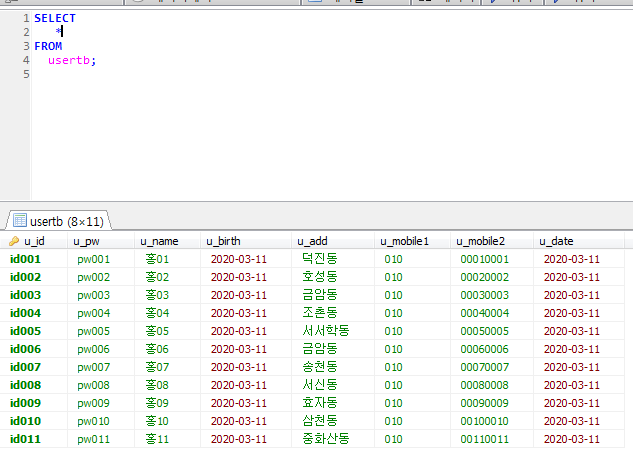
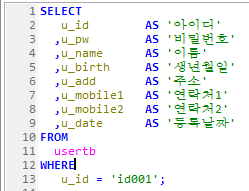
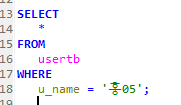
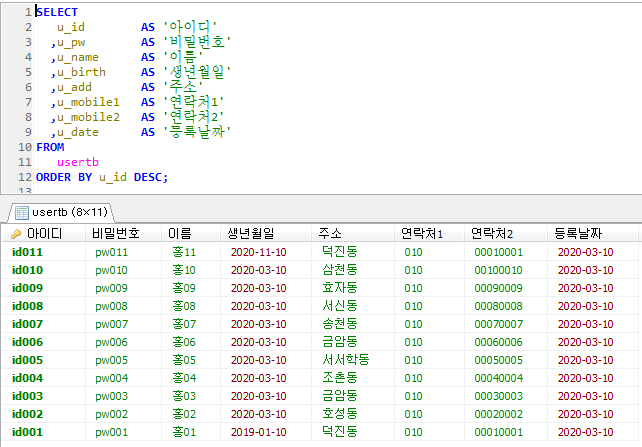
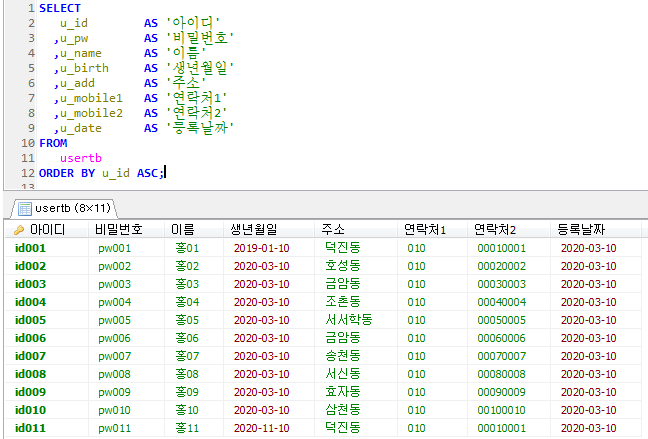
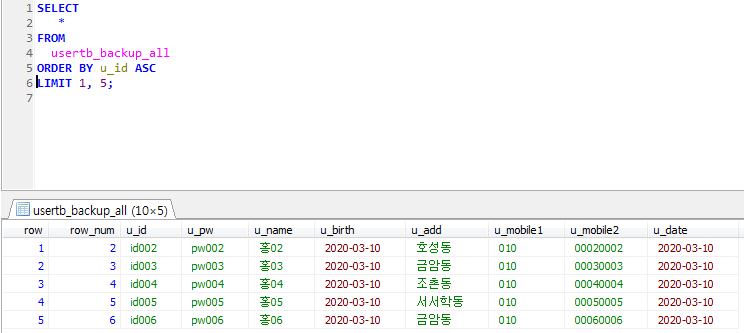
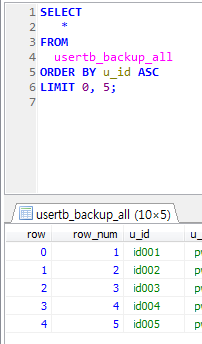
Stored Program
특징
- 일련의 쿼리를 마치 하나의 함수 처럼 실행하기 위한 쿼리의 집합
- MySQL 안에서 프로그래밍 언어와 같은 기능을 제공하는 프로그램 (DML 활용)
- 자주 사용하는 복잡한 쿼리를 하나로 묶어 이름으로 지정하여 이름을 호출하여 실행되도록 설정
- MySQl의 성능 향상
- 긴 쿼리의 내용을 전송하지 않고 프로시저의 이름 및 매개변수 등만 전송하여 네트워크 부하를 줄일 수 있음
- 유지관리가 간편
- 직접 SQL 문을 작성하지 않고 저장된 이름만 호출함으로써 일관된 작업을 함
- 모듈식 프로그래밍 가능
- 한 번 Stored Program을 생성해 쿼리의 수정, 삭제 등의 관리가 수월
- 보안을 강화
- 사용자 별로 테이블에 접근 권한을 주지 않고 Stored Program에 접근 권한을 줌으로써 보안을 강화
종류
- Stored Procedure - 프로시저
- 쿼리문의 집합, 어떠한 동작을 일괄 처리하기 위한 용도로 사용
- 리턴 값이 없다. (단독으로 문장 구성 가능)
- Stored Function - 함수
- 사용자 정의 함수 (내장함수가 제공하지 않는)
- 리턴 값이 있다.(단독으로 문장을 구성할 수 없음)
- Trigger
- 테이블의 동작이 일어나면 자동 실행 (방아쇠)
- 테이블의 DML문이 작동되면 자동으로 실행
- Cursor - 커서
- 테이블에서 여러 개의 행을 쿼리한 후에, 쿼리의 결과인 행 집합을 한 행 씩 철하는 방식
- 일반 프로그래밍의 파일 처리와 비슷한 방법을 제공
Procedure
프로시저의 특징
- 어떠한 동작을 일괄 처리하기 위한 용도
- 자주 사용되는 일반적인 쿼리를 모듈화 시켜 필요할 때만 호출
- MySQL 운영에 편리
프로시저의 단점
- 유지보수 복잡성이 증가 - 각 기능을 담당하는 프로그램 코드가 자바와 MySQL 스토어드 프로그램으로 분산되어 관리하기 때문에 애플리케이션의 설치나 배포가 더 복잡해짐
프로시저의 형식 정의
DELIMITER $$
CREATE PROCEDURE Stored Procedure 이름 (IN/OUT 파라미터)
BEGIN
SQL 프로그래밍 코딩
END $$
DELIMITER;
CALL Stored Procedure 이름();프로시저 형식 실습

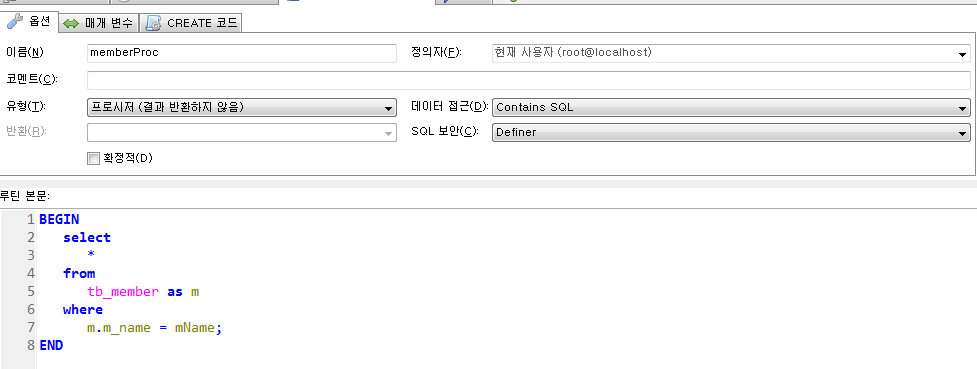
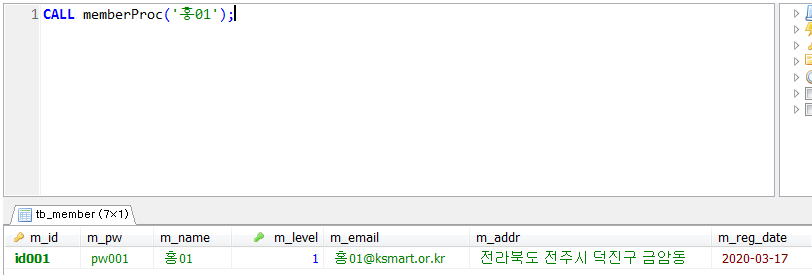
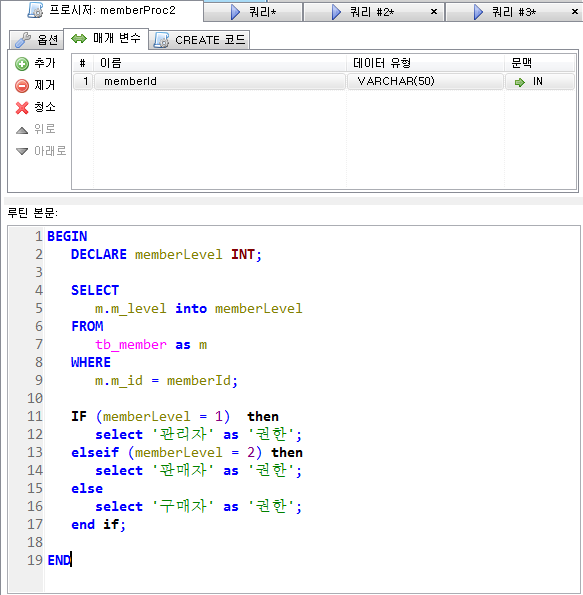
프로시저 실습 (제어문 IF)
DECLARE : 변수선언
DECLARE 변수명 변수타입;
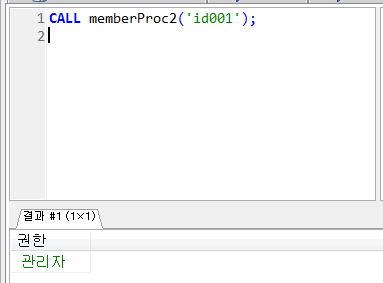
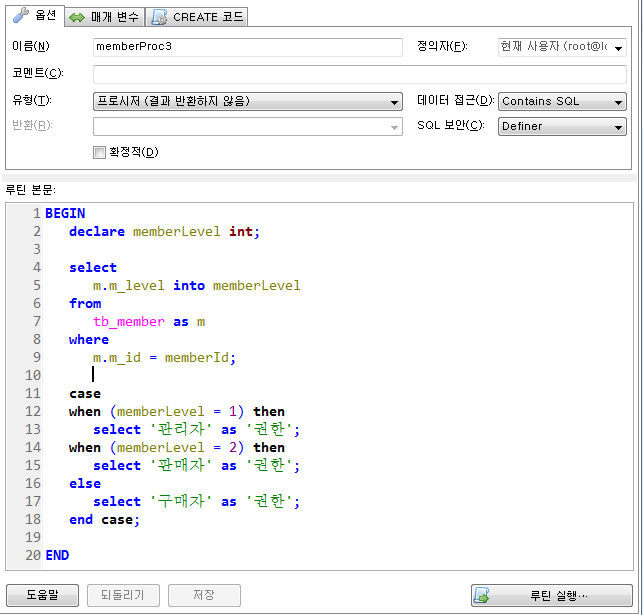
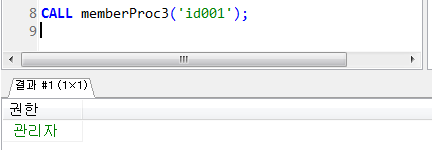
프로시저 실습 (제어문 CASE)
프로시저 실습 (반복문 WHILE)
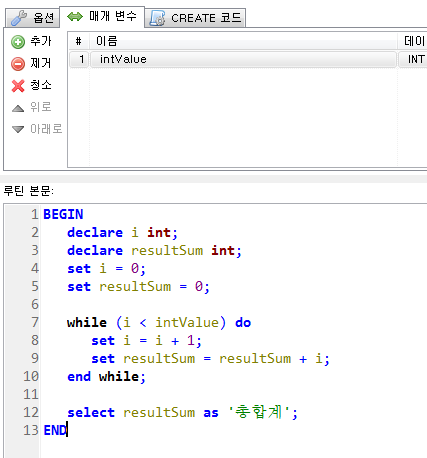
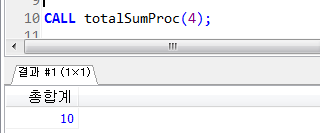
조건문 끝나는 수가 헷갈릴 때 ↓
더보기
while ( n-1 <n ) do
i = n-1+1
result = result + n
n까지 다 돎

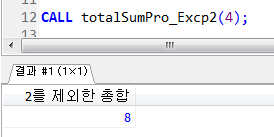
프로시저 실습1
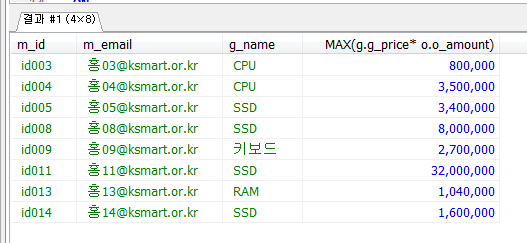
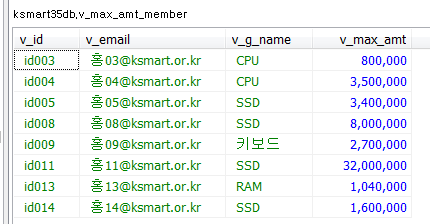
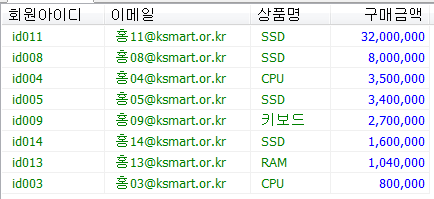
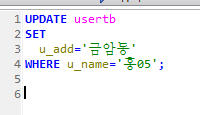
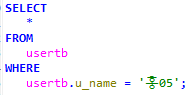
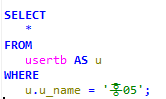
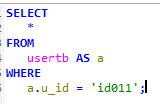
회원테이블의 아이디와 패스워드를 입력받아 일치하는 이메일을 출력하는 프로시저를 생성하고 호출하시오.



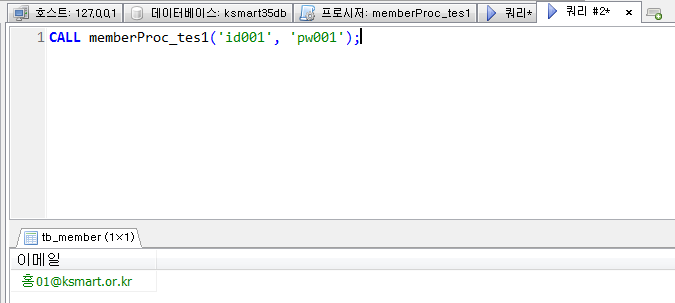
out으로 매개변수에 값을 담아 사용.
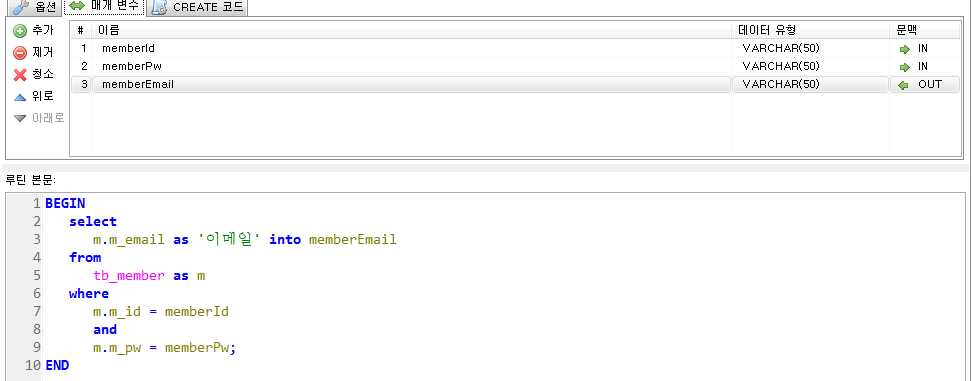
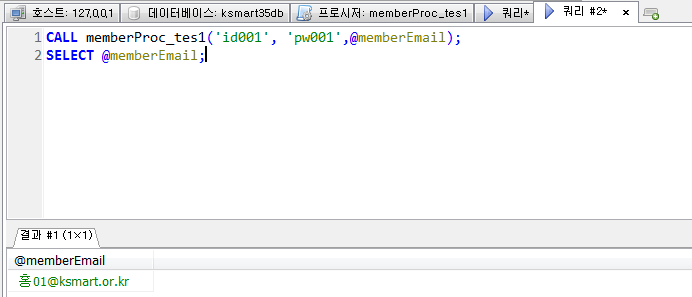
프로시저 실습2
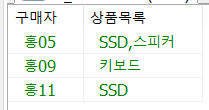
다음과 같이 약수와 약수의 합계를 구하는 프로시저를 만들고 250을 입력받아 호출하여 출력하시오.
WHILE / IF / CONCAT_WS
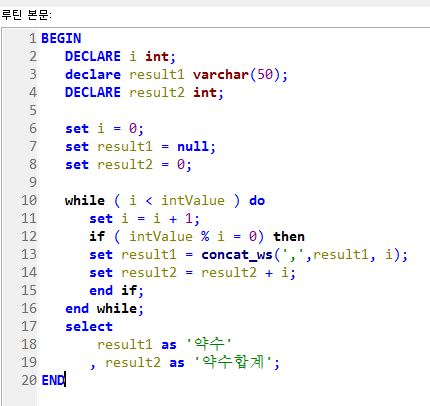
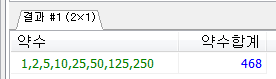
WHILE/ CASE / CONCAT
BEGIN
DECLARE i int;
declare result1 varchar(50);
DECLARE result2 int;
set i = 0;
set result1 = '약수 : ';
set result2 = 0;
while_i: while ( i < intValue ) do
set i = i + 1;
case
when ( intValue % i = 0) and (i = 1) then
set result1 = concat(result1,i);
set result2 = result2 + i;
when ( intValue % i = 0) and (i <> 1) then
set result1 = concat(result1,', ',i);
set result2 = result2 + i;
else
ITERATE while_i;
end case;
end while;
select
result1 as '약수'
, result2 as '약수합계';
END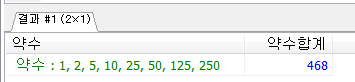
LOOP / IF / CONCAT
BEGIN
declare i int;
declare resultSum int;
declare resultStr varchar(50);
set i = 0;
set resultSum = 0;
set resultStr = '';
LOOP_sum : LOOP
if ( i = intValue) then
leave LOOP_sum;
end if;
set i = i+1;
if((intValue % i) = 0) then
set resultSum = resultSum + i;
if(i = 1) then
set resultStr = concat ('약수 : ',i);
else
set resultStr = concat (resultStr, ', ', i);
end if;
end if;
end loop;
select
resultStr as '약수'
,resultSum as '약수총합';
END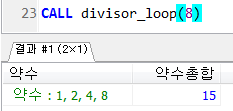
jdbc procedure call
'Database' 카테고리의 다른 글
| [Database] SQL VIEW (0) | 2020.04.06 |
|---|---|
| [Database] Sub Query / UNION (0) | 2020.04.01 |
| [Database] 정규화(Normalization) (0) | 2020.04.01 |
| [Database] 데이터베이스 설계 (0) | 2020.03.25 |